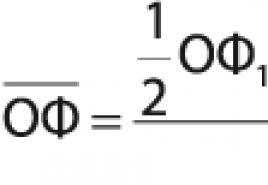Učestalost implantacije riječi. Učestalost slova u ruskom jeziku. Zašto se nazivi i skraćenice vide u okremy listi
Učestalost blokiranih slova na ruskom jezikuA znate da se neka slova abecede koriste u riječima češće od drugih... Štaviše, učestalost živopisnosti zvučnih slova u jeziku je veća, niže glasna.
Kako se slova ruskog alfabeta najčešće koriste u riječima koje se pišu za pisanje teksta?
Statistika se bavi manifestacijama i relevantnim pravilnostima. Uz pomoć naučnog direktnog, možete pronaći odgovore na pitanje prehrane, poboljšati broj kožnih slova u ruskoj abecedi, sastaviti riječi, odabrati stihove iz djela raznih autora. Iz ličnog interesa i radi zapošljavanja u koži, možete raditi sami. Pa, osvrnuću se na statistiku već sprovedene studije...

Rusko pismo ćirilica. Za sat vremena, temelj vina preživio je prskanje reformi, koje su razvile moderni ruski abecedni sistem, koji uključuje 33 slova.

za - 9,28%
a - 8,66%
e - 8,10%
i - 7,45%
n - 6,35%
t - 6,30%
p - 5,53%
h - 5,45%
l - 4,32%
c - 4,19%
do - 3,47%
n - 3,35%
m - 3,29%
y - 2,90%
e - 2,56%
i - 2,22%
s - 2,11%
b - 1,90%
h - 1,81%
b - 1,51%
g - 1,41%
th - 1,31%
godine - 1,27%
yu - 1,03%
x - 0,92%
w - 0,78%
w - 0,77%
c - 0,52%
u - 0,49%
f - 0,40%
e - 0,17%
b - 0,04%
Rusko pismo, koje ima najveću frekvenciju u vikoristannym - je glasno " Pro”, Yak je s pravom bio dopušten ovdje. Ê-ta karakteristična zadnjica, na kshtaltu" ODBRANA” (7 komada jednom riječju i ništa egzotično, čudesno; to je još izraženije za ruski film). Velika popularnost slova "O" bogata je onim što se objašnjava takvim gramatičkim fenomenom, poput publiciteta. Tobto "hladno" zamjenjuje "hladno", a "mraz" zamjenjuje "ološ".
A na samom klipu jezika najčešće se čuje slovo. P". Liderstvo se također podrazumijeva i nečuvano. Shvidshe za sve, objašnjenje daje veliki broj prefiksa sa slovom "P": re-, pre-, before-, at-, pro-ta ínshí.
Učestalost različitih slova je osnova kriptoanalize.
Želim da napredujem, koje informacije, šta je uključeno u ovaj članak, su zastarele. Nisam postao njen prepisivač, da bih kasnije mogao da uporedim kako se SEO standardi menjaju iz sata u sat. Ažurne informacije o ovoj temi možete pronaći u novim materijalima:
Pozdrav, novi čitaoci blog stranice. Današnji članak će opet biti posvećen takvim temama, poput optimizacije web stranica za pretraživače. Ranije smo već naleteli na bogatu hranu, vezani takvim shvatanjima, kao.
Danas želim da nastavim da pričam o internom SEO-u, da razjasnim šta se ranije desilo, a takođe i da pričam o onima o kojima još nije bilo reči. Iako pišete dobre unikatne tekstove, ali ako ne poštujete pretragu po sistemima za pretraživanje, onda smrad neće moći da se probije do vrha pretrage po zahtjevima vezanim za temu vaših divnih članaka .
Šta utiče na relevantnost teksta za zahtev za pretragu
A to je još nejasnije, jer na taj način ne ostvarujete puni potencijal svog projekta, koji se može učiniti još značajnijim. Neophodno je razumjeti koji su sistemi pretraživanja svijeta - to su glupi i jednostavni programi, koji vam ne dozvoljavaju da pređete svoje mogućnosti i pogledate svoj projekat ljudskim očima.
Ne možete smrditi puno svega što je dobro i potrebno za vaš projekat (ono što ste pripremili za projekat). Smrad vmíyut manje analizira tekst, vrakhovuuchi u isto vrijeme bogato skladište, ale smrdi, kao i prije, već daleko od ljudskog spryyatt.
Kasnije ćemo morati neko vrijeme htjeti ući u cipele robota za pretraživanje i razumjeti na šta bi se smrad trebao fokusirati kada rangiramo različite tekstove za različite upite za pretraživanje (). I kome je potrebno da majka toga bude svjesna, kome će biti potrebno da bude svjesna citiranog članka.
Ozvučite odabrane ključne riječi u naslovu stranice, u nekim internim naslovima, i jednako je prirodnije i prirodnije podijeliti ih za članak. Dakle, suludo, vidjeti ključeve u tekstu također se može pokvariti, ali ako ne želite zaboraviti na ponovnu optimizaciju, za koju možete biti.
Važna je i sama važnost unosa ključeva u tekst, ali u isto vrijeme, to nije loš faktor, već ćemo vas, naprotiv, čuvati - ne možete pretjerati.
Lako je dobiti vrijednost ključnog unosa u dokument. Naime, učestalost izbora istog u tekstu, jer je određena razlikom u broju unosa u dokument za dužinu dokumenta u riječima. Ranije je postojalo mjesto za lokaciju vrste.
Ali vi ste, sami, shvatili da je nemoguće sastaviti sav materijal samo iz ključeva, jer ga nećete čitati, hvala Bogu da nije potrebno raditi. sta pitas Dakle, ako postoji razlika u učestalosti ključne riječi u tekstu, ako relevantnost dokumenta za zahtjev, da se osveti ovaj ključ, neće biti promovirana.
Tobto. biće nam dovoljno da dostignemo frekvenciju pjevanja i na taj način je maksimalno optimiziramo. Inače ćemo pretjerati i koristiti filter.
Ostale su dvije riječi (ili možda tri): koja je maksimalna širina unosa ključa, ako ga već nije bezbedno koristiti, pa je samo po sebi razumljivo.
Desno, utoliko što su ključne riječi, gledane sa naglašenim oznakama i smještene u oznaku TITLE, možda važnije za šalu, niže slične tipke, koje su jednostavno ispisane u tekstu. U ostatku sata, webmasteri su se počeli javljati i sve više spamovati ovaj faktor, u vezi s čim je njegova vrijednost opala i može dovesti do zabrane cijele stranice kroz zlonamjerne napade jakih osoba.
Ale tipke u NASLOVU, kao i do sada, relevantne, što bolje moguće, ne ponavljaju se tu i ne guraju previše u jednu stranu zaglavlja. Ako će TITLE imati ključne riječi, onda možemo promijeniti broj riječi u članku (što znači da je lak za čitanje i pristupačniji ljudima, a ne poke sistemima), dostižući istu relevantnost, ali ne rizikujući korištenje filtera .
Mislim da im je sve bilo jasno - što više ključnih riječi bude stavljeno u naglašene TITLE tagove, veće su šanse da potroše sve odjednom. Ali ako ih ne osvojimo, onda nećete ništa postići. Najvažniji kriterijum je prirodnost postavljanja ključnih reči u tekstu. Kao smrad, ali čitalac se ne spotiče o njima, sve je divno.
Sada više nema istraživanja, a kako je frekvencija ključne riječi u dokumentu optimalna, jer vam omogućava da kreirate najrelevantniju stranu, nemojte izricati sankcije. Počnimo tako što ćemo pogoditi formulu, kako osvojiti najviše (pevajući, pevajući) nasumičnih sistema za rangiranje.
Kako odrediti dozvoljenu učestalost implantacije ključa
Već smo ranije govorili o matematičkom modelu pogađanja više statistike. Suština specifičnog upita upita je izražena jednom jednostavnom formulom: TF*IDF. De TF - ovo je direktna frekvencija unosa ovog zahtjeva u tekst dokumenta (frekvencija za koju se pjevaju riječi).
IDF - učestalost vraćanja populacije (rídkísníst) ovog zahtjeva u drugim dokumentima na Internetu, indeksiranim ovim sistemom pretraživanja (u kolekciji).
Ova formula vam omogućava da odredite relevantnost (relevantnost) dokumenta prije upita. Što je važniji rad TF*IDF, to će dokument biti relevantniji, a mi ćemo se više zalagati za druge jednake umove.
Tobto. da izađe, koji će dokument za dati zahtjev (yogo dokaz) biti veći, što se ključevi ovog zahtjeva češće citiraju u tekstu, a što se ključevi češće navode u drugim dokumentima na internetu.
Shvatio sam da ne možemo ući u ID, ako izaberemo drugi zahtjev, možemo ga optimizirati. A osovinu možemo koristiti na TF i hoćemo, ako želimo svoj dio (i to ne mali) prometa od Yandex i Google gledatelja iskoristiti sa hranom koja nam je potrebna.
S druge strane, činjenica da algoritmi pokušavaju da odgonetnu vrijednost TF koristeći škakljivu formulu, kao što je veća frekvencija ključnih riječi u tekstu samo do granice pjevanja, ako je povećanje TF praktično, bez obzira na one kojima povećavate frekvenciju. To je neka vrsta filtera protiv neželjene pošte.
Dugo vremena (otprilike do 2005.) vrijednost TF se mijenjala jednostavnom formulom i, u stvari, bila je jednaka širini unosa ključne riječi. Rezultati potrage za relevantnošću ove formule nisu bili slični džokerima, već spamerima.
Tada se formula TF zakomplikovala, postala je jasnija kao zamor sa strane i van depozita kao po učestalosti ulaska, ali i po učestalosti unošenja drugih riječi u taj tekst. Í optimalna vrijednost TF se može postići, jer se ključ najčešće prikazuje ugrađenom riječi.
Također je moguće povećati vrijednost TF uz pomoć povećanja veličine teksta iz čuvanja unosa. Što će ručnik biti veći za artikal, sa istim brojem ključeva, to će dokument stajati veći.
Sada je TF formula postala još složenija, ali u isto vrijeme nemamo potrebu dovoditi vrijednost na tu vrijednost, ako tekst postane nečitljiv nametnuti sistem pretraživanja zabrana našeg projekta zbog neželjene pošte. To pisanje nesrazmjerno rastegnuto u isto vrijeme, nema potrebe.
Uz uštedu tíêí̈ i íí̈í̈ ídealíí̈ í̈ílností (i íí̈ značajno niže z vídpovídnogo grafa), zbílshennya rozmíru statti u riječima í̈í̈ poshchuvatime ííí̈ položaj u vrsti samo da bi se dospjelo do pjevanja dozhina. Osim toga, kako ste imali idealan život, što dalje, nećete se trošiti na relevantnost (tačnije, naizgled će biti, ali sve više i više nedovoljno).
Sve se može uraditi na licu mjesta, tako da se raspored bazira na škakljivoj TF (direktna ulazna frekvencija). Ako će na jednoj skali grafikona biti TF, a na drugoj skali stota učestalost ključne riječi u tekstu, onda ćemo kao rezultat uzeti takozvanu hiperbolu:

Grafikon je, očito, približan, ali TF formula je stvarna, kao Yandex ili Google, malo ljudi zna. Možeš računati optimalan domet, koji može imati frekvenciju. Cijena je otprilike 2-3 vídsotki u íd alaní̈ ílkoí̈ ílkostí sív.
Ako lažete, ako stavite dio ključnih riječi u oznaku naglašenog naslova TITLE, onda će postojati takva granica, ako svako daljnje povećanje snage može zaprijetiti zabranom. Više nije isplativo pjevati i promovirati tekst na veliki broj ključnih riječi, jer će biti više minusa, manje plusa.
Yaka dozhina tekst će biti dovoljan za prolazak
Na osnovu istog, prenoseći TF, možete inducirati graf upadljivosti i značenja u riječima. Uz to, možete uzeti frekvenciju ključnih riječi konstante za to da li je duga i jednaka, na primjer, da li je vrijednost iz optimalnog raspona (na primjer, 2 do 3 vídsotkív).
Ono što je vrijedno pažnje, oduzimamo graf takve forme, kao da se više gleda, samo će na osi apscise biti obogaćen tekstom u hiljadama riječi. Í z o optimalan raspon života, ako je maksimalna vrijednost TF praktično na dohvat ruke.
Kao rezultat, čini se da je u rasponu od 1000 do 2000 riječi. Daljnjim povećanjem relevantnost se praktično ne povećava, a sa manjim povećanjem naglo se smanjuje.
Incl. Moguće je kreirati vysnovok, tako da bi vaši članci zauzeli visoko mjesto u pretraživanju videa, potrebno je istaknuti ključne riječi u tekstu sa učestalošću ne manjom od 2-3%. Prvi je glavni visnovok, koji smo zgnječili. Pa, i onaj drugi - oni koji odjednom ne moraju pisati više o člancima da bi došli do Topua.
Da biste došli do vrha u 1000 - 2000 riječi i uključili u novih 2-3% ključnih riječi. Os i sve ts i ê recept za savršen tekst, koji će se takmičiti za mjesto u vrhu u vrhu po potražnji niske frekvencije, a da ne mora pobijediti na originalnoj optimizaciji (kupovina poruke za članak sa sidrima, koja uključuju ključeve). Hocha, pojedi malo trochova Miralinks , GGL, Rotaposte ili GetGoodLinci mogu vam pomoći s vašim projektom.
Još jednom ću vam reći o dužini teksta koji ste napisali, kao i o učestalosti navikavanja na nove tihe i druge ključne riječi, možete se obratiti za pomoć u specijalizovanim programima ili za pomoć sa online servisima koji specijalizovani za ove analize. Jedna od ovih usluga je ISTIO o poslu s kojim sam rozpovidav.
Sve o čemu sam više rekao nije tačno, već je još sličnije istini. Prihvatite moje specijalnosti da potvrdite ovu teoriju. Ali algoritmi rada Yandexa i Googlea će stalno prepoznavati promjenu i kako će biti sutra, malo ljudi zna, krim je tih, tko je blizak njihovom rozrobki ili rozrobnikív.
Sretno ti! Za brzo zustríches na stranama blog stranice
Možeš buti cikavo
 Interna optimizacija - odabir ključnih riječi, ponovna provjera gluposti, optimalni naslov, dupliciranje sadržaja i ponovno povezivanje subwoofera
Interna optimizacija - odabir ključnih riječi, ponovna provjera gluposti, optimalni naslov, dupliciranje sadržaja i ponovno povezivanje subwoofera  Ključne riječi u tekstu i naslovima
Ključne riječi u tekstu i naslovima  Kako ubaciti ključne riječi na web lokaciju putem pretraživača
Kako ubaciti ključne riječi na web lokaciju putem pretraživača  Online usluge za webmastere - sve što vam je potrebno za pisanje članaka, optimizaciju za pretraživače i analizu i uspjeh
Online usluge za webmastere - sve što vam je potrebno za pisanje članaka, optimizaciju za pretraživače i analizu i uspjeh  Načini optimizacije sadržaja i izgleda subjekta sajta pri slanju na link su minimalni
Načini optimizacije sadržaja i izgleda subjekta sajta pri slanju na link su minimalni  Yandex Wordstat i semantičko jezgro - izbor ključnih riječi za stranicu za dodatnu statistiku za online uslugu Wordstat.Yandex.ru
Yandex Wordstat i semantičko jezgro - izbor ključnih riječi za stranicu za dodatnu statistiku za online uslugu Wordstat.Yandex.ru  Sidro - šta je isto i koliko smrdi je važno za web stranicu
Sidro - šta je isto i koliko smrdi je važno za web stranicu  Kao faktori optimizacije za pretraživače ubrizgati u sajt koji takav svet
Kao faktori optimizacije za pretraživače ubrizgati u sajt koji takav svet  Promocija, promocija i optimizacija stranice samostalno
Promocija, promocija i optimizacija stranice samostalno  Oblik morfologije filma i drugi problemi razvoja zvučnih sistema, kao i kontrola HF, MF i NF ulaza
Oblik morfologije filma i drugi problemi razvoja zvučnih sistema, kao i kontrola HF, MF i NF ulaza  Poverenje sajtu - kako je osvojiti u XTools, šta će to dodati novom i kako povećati autoritet vaše stranice
Poverenje sajtu - kako je osvojiti u XTools, šta će to dodati novom i kako povećati autoritet vaše stranice
Pisanjem smiješne php skripte. Poganjav kroz sve tekstove na "Spektorima" na temu filma. U tekstovima je pobjedničko 39110 različitih oblika riječi. Skílki most raznih slív- Teško je završiti. Ako želim da se približim cifre tsíêí̈, uzimam samo prvih 5 slova riječi i porívnyuvav ih. Bilo je 14 373 takve kombinacije. Uz veliku nategnu, to se može nazvati Spectorovom zalihom riječi.
Zatim sam uzeo riječi i završio ih prema učestalosti ponavljanja slova. U idealnom slučaju, trebate uzeti rječnik da biste upotpunili sliku. Tekstove ne možete preskočiti, potrebne su vam samo jedinstvene riječi. U tekstu se neke riječi ponavljaju češće, rjeđe. Otzhe, vyyshli takve rezultate:
za - 9,28%
a – 8,66%
e – 8,10%
ta - 7,45%
n - 6,35%
t - 6,30%
p - 5,53%
h - 5,45%
l - 4,32%
c - 4,19%
do - 3,47%
n - 3,35%
m - 3,29%
y - 2,90%
e - 2,56%
i - 2,22%
- 2.11%
b – 1,90%
h – 1,81%
b - 1,51%
d – 1,41%
th - 1,31%
godine – 1,27%
yu - 1,03%
x - 0,92%
g – 0,78%
w – 0,77%
c - 0,52%
w - 0,49%
f - 0,40%
e - 0,17%
b - 0,04%
Tim, koji će ići na Polje čuda, raja treba da zapiše ovu tabelu u pamćenje. I imenuje riječi ovim redoslijedom. Tako je, na primjer, dato b, takvo "zvično" slovo "b" se više koristi, niže "redkishno" slovo "i". Sjećanje je potrebno i onima koji imaju više od jednog glasa. A ako ste pogodili jedan glas, onda je potrebno krenuti za pravim. Osim toga, riječ se sama pogađa iza glasa. Izjednačite: “**a**í*e” i “ekvivalent*t*”. I u tom i u drugom zaokretu - cijela riječ "privnyayte".
I još jedan mirkuvannya. Kako ste naučili engleski? Sjećaš li se? E olovka, e penzija, e stol. O čemu pričam - o njima spavam. A smisao?.. Koliko često izgovarate riječ "olívets" u normalnom životu? Ako je to zadatak - naučite reći da je djelotvorniji i djelotvorniji, onda ga je potrebno jasno pročitati. Radimo analizu filma, vidimo riječi koje nalazimo. I sami pročitajte od njih. Jecaj manje-više govori engleski, dovoljno je ponoviti hiljadu riječi.
Još jedna pustoš: stavite riječi sa slovima u vipadkovy rang, a zatim se pojavljuju s drugom frekvencijom, tako da izgleda kao normalna riječ. Na prvih deset "vipadkovih" čotirilternih riječi, "magarac" je iskočio. U ofanzivi pívsotní - riječi "jurnjava" i "nato". Ali, nažalost, postoji mnogo disonantnih kombinacija, poput “bltt” ili “nrro”.
Za to - nadolazeći crk. Kasnije sam sve riječi razbio u dva termina i počeo vipadkovo (iako uz poboljšanje učestalosti ponavljanja) da ih kombinujem. Veliki broj je počeo da viđa reči slične "normalno". Na primjer: “koí̈vdiot”, “voabma”, “apy”, “depoid”, “debyako”, “orpha”, “poesnavi”, “ozza”, “chenya”, “retorika”, “urdeêd”, “utoichi” , "Verse", "Sapot", "Gravda", "Ababap", "Obarto", "Eluy", "Lyarezi", "Mini", "bromomer" i tip "todebist".
Kudi zastosuvat ê opcije. Na primjer, napišite generator prekrasnih korporativnih sivih imena. Za jogurt. Kao, "memolíso" ili "utororerto". Abo je generator futurističkih stihova "Burlyuk-php": "opeldia miaton, linoaz okmia ... deesopen odeson".
Još jedna opcija. Treba probati...
Stvarni statistički podaci o ruskoj literaturi:
- Srednja dožina simbola riječi 5.28.
- Sredina dana 10.38 slív.
- 1000 najčešćih frekvencija pokrivaju 64,0708% teksta.
- 2000 najčešćih riječi pokrivaju 71,9521% teksta.
- 3000 najčešćih ključnih riječi pokrivaju 76,5104% teksta.
- 5000 najčešćih frekvencija pokrivaju 82,0604% teksta.
Nakon bilješke, dobio sam takav list:
Zdravo Dmitre!Nakon analize članka “Mova u Kijev donijela” taj dio, de Wee opiše vaš program, došla je ideja.
Time što pišete scenario, prepoznaću ga apsolutno ne za Polje čuda većeg sveta, već za onaj drugi.
Prvo najrazumnije dimenzionisanje rezultata rada vaše skripte je dodeljivanje redosleda slova prilikom programiranja dugmadi za mobilne uređaje. Dakle, tako - u mobilnim telefonima i sve je potrebno.I rozpod_liv tse na hvilyah ()
Dali ruža za dugmad:
1. Sva slova iz prvog idu u prvi red u prvom redu
2. Sva slova iz drugih počasnih slova na liniji od 4 dugmeta u istom prvom redu
3. Sva slova iz trećeg dok nedostaju dva dugmeta.
4. 4.5 i 6 hvili idu u drugi red
5. 7,8,9 hvili idu u treći red, štaviše, 9. hvili idu skroz (nemojte se čuditi velikom broju slova) do trećeg reda 9. dugmeta, tako da je 10. dugme uklonjen iz svih vrsta različitih znakova tamo (maglica, koma ili drugo).Mislim da je sve shvaćeno i tako, bez detaljnih objašnjenja. Al, svejedno, nisi mogao koristiti svoju skriptu (uključujući znakove zakačenja) teksta napada:
A zgodom viklasti statistiku? Jesam li dobio? da tekstovi što više odražavaju naš današnji jezik, i kako mi kažemo, tako i pišemo sms.
Hvala vam puno unapred.
Opet, učestalost ponavljanja slova može se analizirati na dva načina. Metoda 1. Uzmite tekst, upoznajte nove jedinstvene (ne ponovljene) oblike riječi i analizirajte ih. Način da se statistika dobije iza riječi ruskog jezika, a ne iza tekstova. Metoda 2. Nemojte mešati jedinstvene reči u tekstu, već odmah pređite na učestalost ponavljanja slova. Oduzimamo učestalost slova u ruskim tekstovima, ali ne i u ruskim riječima. Za izradu tastatura i drugih potrebno je kucati na isti način: tekstovi se kucaju na tastaturi.
Tastature su krive ne samo za učestalost slova, već i za najvažnije riječi (oblike riječi). Nije toliko važno pogađati, kao same riječi koje saznate: tse, first, usluge dio mov, jer njihova uloga je ovakva - služe zauvijek i skríz, ja zajmoprimci, uloga nekih nije manje važna: zamijenite u mov ako ste rijeka / osoba (tse osvojio, osvojio). To i glavne riječi (buti, reci). Za rezultate analize vaskrslih tekstova oduzeo sam takve „popularne“ riječi: „ja, ne, in, sho, vin, ja, na, s, pobijedio, yak, ale, yogo, tse, do, a, sve, í̈í̈, bulo, pa, ali, onda, govoreæi, za, ty, oh, y, yoma, ja, samo, za, manje, b, tako, vy, vid, buv, ako, s, za, više, sad, smrdi, rekao, već, yogo, ní, bula, í̈y, buti, pa, ní, yakscho, duzhe, ništa, os, sebi, shob, sobi, tsgogo, možda više, to, mi, njih, chi, buli, ê, chim , inače, níy” i tako dalje.
Okrećemo se tastaturama - očito je da su na tastaturi slova "not", "scho", "vin", "on" i druge odgovornosti bliži jedan prema jedan, inače nije tijesno, onda se čini da je najoptimalnije rang. Potrebno je izvršiti praćenje, istim redoslijedom spuštanja prstiju na tastaturu, znati najpogodnije pozicije i postaviti u njih najpoznatija slova, ne zaboravljajući, prote, za pismo.
Problem je, kao i uvek, isti: kako napraviti jedinstvenu tastaturu, gde milioni ljudi idu, kao da su već pozvali na qwerty/yutsuken?
Ima mobilnih dodataka... Bez sumnje, ima smisla. Prihvatite, slova "o", "a", "e" i "i" moraju biti potpuno na istom ključu. Razdíloví znakovi po učestalosti uvođenja: , . -? ! ; :) (
Kratak opis problema
Ê zbirka datoteka sa ruskim tekstovima u literaturi različitih žanrova do ažuriranja vijesti. Potrebno je odabrati statistiku života primalaca sa ostalim dijelovima promocije.
Važni trenuci na čelu
1. Među nasljednicima nema ništa manje atі prije, ale stiyki poednannya sliv, scho se navikne kao nasljednik, npr. u luci ili bez obzira na. Stoga nije moguće jednostavno ispraviti tekstove zbog praznina.
2. Tekstovi su bogati, kílka GB, dužnost je radnika završiti šved, prihvatiti, uklopiti se u kílku godine.
Mala rješenja i rezultati
Vrahovyuchi nayavny vyvíd vyvíd vyvíd vyvíd vyvíd vídíshnya vídíshennya z obrobkoyu tekstív, vírisheno dotrimuvatís modifíkovannogo "unix-way", a sama - razbítívíd vyvíd vídíshnya vídíshennya z obrobkoyu tekstív, vírisheno dotrimuvatís modifíkovannogo "unix-way", a sama - tako razbítívíd ín ípívíd ípích íních. Sa stanovišta čistog unix načina, umjesto da prenosimo tekstualni fajl kroz kanale, štedimo sve od gledanja datoteka na disku. Dobre broj gigabajta na tvrdom disku nije mali.
Skin stage je implementiran kao krema, mali i jednostavan uslužni program koji čita tekstualne datoteke i čuva proizvode svog silikonskog života.
Dodatni bonus takvog pristupa, osim jednostavnosti uslužnih programa, temelji se na inkrementalnom rješenju - možete poboljšati prvi korak, proći kroz novi sve gigabajte teksta, a zatim početi prilagođavati drugi korak bez trošenja sat vremena o ponavljanju prvog.
Podijelite tekst u riječi
Pošto su originalni tekstovi koji se koriste za obradu već sačuvani kao ravni fajlovi kodirani u utf-8, onda je nulta faza raščlanjivanje dokumenta, raščlanjivanje teksta umesto i čuvanje od gledanja jednostavnih tekstova, preskakanje, odmah prelazak na tokenizaciju.
Sve bi bilo jednostavno i zamorno, nije jednostavna činjenica da su đakoni doneli Rusu formirani u dekilkoh redovima, koji su podijeljeni razmakom, ali ponekad i komom. Da ne bih otkrio tako bogato povezane pojmove, dobio sam funkciju tokenizacije u API-ju rječnika. Raspored u C# je jednostavan i nekompliciran, doslovno stotine redova. Axis vyhídnik. Čim uđete u dio, zaplitanje rječnika i njegov završni dio, sve se penje na opkladu na desetine redova.
Sve je uspješno pamti- belyuê datoteke, ali na testovima se pojavilo suttêviy nedolík - čak nisko swidkíst. Približno 0,5 Mb/hv korišteno je na x64 platformi. Očigledno, tokenizator je drugačiji u svakom pogledu. A.S. Puškin“, Ale, za završetak vikend zadatka, ovakva tačnost zadatka.
Kao vodič za mogućnost brzine, korisnost statističke obrade fajlova u Empiriki. Trebat će oko 2 godine da se završi frekvencijska obrada 22 GB tekstova. Tamo ima sve više uobičajenih rješenja za problem bogatih uzroka, pa sam dodao novu skriptu koja uključuje opciju -tokenize na komandnoj liniji. Prema rezultatima, trčanje je trajalo oko 500 sekundi na 900 MB, što je blizu 1,6 MB u sekundi.
Rezultat rada sa 900 Mb teksta je datoteka približno iste veličine, 900 Mb. Koža riječi je sačuvana na kremastom redu.
Učestalost implantacije recipijenata
Tako da nisam htio u tekst programa unositi listu prijemnika, opet sam dodao gramatički rječnik u C# projekat, uz pomoć funkcije sol_ListEntries uklonio sam cijelu listu prijemnika, oko 140 komada, ali tada je sve bilo trivijalno. Tekst programa u C#. Nećete uzeti opkladu na primaoca + reč, već proširite probleme u skladištu.
Obrada tekstualne datoteke od 1 GB sa 3 riječi traje manje od malo vremena, rezultati će imati tabelu učestalosti, koja izgleda kao tekstualna datoteka na disku. Prijemnik, druga riječ je broj vzhitkív vídokremlíní u novom simbolu tabele:
PRO ROZBIT 3
O ZABORAVI 1
PRO OBRAZAC 1
PRO NORM 1
PRO POST 1
PRAVNI 9
3 TERASE 1
ZANEMARUJUĆI ISTEZANJE 1
PREKO FADICA 14
U posljednjih 900 MB, tekst je primio oko 600.000 parova.
Analiza i pregled rezultata
Tabela sa rezultatima može se ručno analizirati u Excel-u i Access-u. Ja sam preko zvichka na SQL zavantazhiv dani u Access.
Prva stvar koju možete učiniti je sortirati rezultate po redoslijedu promjene učestalosti kako biste napravili najbolju opkladu. Ishod pokvarenog teksta je premali, tako da izbor nije reprezentativan i može se suditi po rezultatima sub-bag, već prvih deset:
IMAMO 29193
U VOLUME 26070
Imam 25843
PRO VOLUME 24410
NA NOVU 22768
CYOGO 22502
NA PODRUČJU 20749
PID SAT 20545
PRO CE 18761
Z NIM 18411
Sada možete indukovati graf, tako da su frekvencije bile na OY osi, a obrasci lebdeli na OX osi za pad. Tse dati puno ochíkuvaniya rozpodíl íz željezni rep:
Nova potrebna statistika
Osim toga, dva C# uslužna programa mogu se koristiti za demonstraciju rada sa proceduralnim API-jem, a metapodaci prijevoda i algoritam rekonstrukcije teksta statistički su važniji. Krím parovi će također biti potrebni trigrami, za koje ćete morati proširiti uslužni program za prijatelja.
- - Teme za zahistu informacije EN učestalost upotrebe riječi... Tehnički prevod Dovídnik
s; frekvencije; i. 1. do Delova (1 cifra). Pratite učestalost ponavljanja šetnji. Potrebna godina. sadnja krompira. Obratite pažnju na brzinu pulsa. 2. Broj ponavljanja istog ruhív, colivan na yaku l. jedan sat. Ch.wrap. H… Enciklopedijski rječnik
I Alkoholizam je hronična bolest koju karakteriše niz psihičkih i somatskih poremećaja, koji se okrivljuju za sistematsko konzumiranje alkohola. Najvažnije manifestacije A. x. ê Vitrivalitet je promenjen u… Medicinska enciklopedija
BURNING- jedan od specifičnih pojmova koji se nalaze u takvim zapisima Rusije. bezlinski bogati glas, koji karakteriše različit podglasovni polifoni sklad i oštra disonanca vertikale. Spivch. primjena termina u sadašnjosti. vrijeme bez mahanja... Orthodox Encyclopedia
Stilostatistička metoda analize teksta- - svrha postavljanja alata matematičke statistike u sferu stila, određivanje tipova funkcionisanja filma u filmu, zakonitosti funkcionisanja filma u različitim oblastima komunikacije, vrste tekstova, specifičnosti funkcija. stilovi i…
Porcija aromatiziranog snusa, mini porcija Snusa je vrsta tyutyun virobua. To je detalj zadataka tyutyun-a, koji je postavljen između gornje (ili donje) usne i jasan.
Naučni stil- predstavljanje nauka. sfera međuigre i kretanja aktivnosti, povezana sa implementacijom nauke kao oblika gipkosti; odražava teorijsku ideju, koja je predstavljena u konceptualnom i logičkom obliku, koju karakterizira objektivnost i višeznačnost. Stilistički enciklopedijski rečnik ruskih filmova
- (Specijalna literatura ima i patrone) dio prezimena, jer se djetetu pripisuje ime oca. Varijacije patronimskih imena mogu dočarati njihove nosove i udaljenije pretke kao bake i djedove.
Zastosovníst, zastosovníst, širina, zastosovníst, hodkíst, zagalnopriynyatíst Rječnik ruskih sinonima. spontanost br., kíl blizu sinonima: 10 pohlepno prihvaćanje (11) ... Pojmovnik sinonima
Mírkuvannya- - funkcionalno smislena vrsta filma (div.) - (FSTR), glavni oblik apstraktne misli - visnovka, koja čini poseban komunikativni zadatak - daju pokretu argumentacijskog karaktera (dođite na logičan način do novog suda ili ... ... Stilistički enciklopedijski rečnik ruskih filmova